Big data -Simple learning
“Big data” is high-volume, -velocity and -variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.



Hadoop -








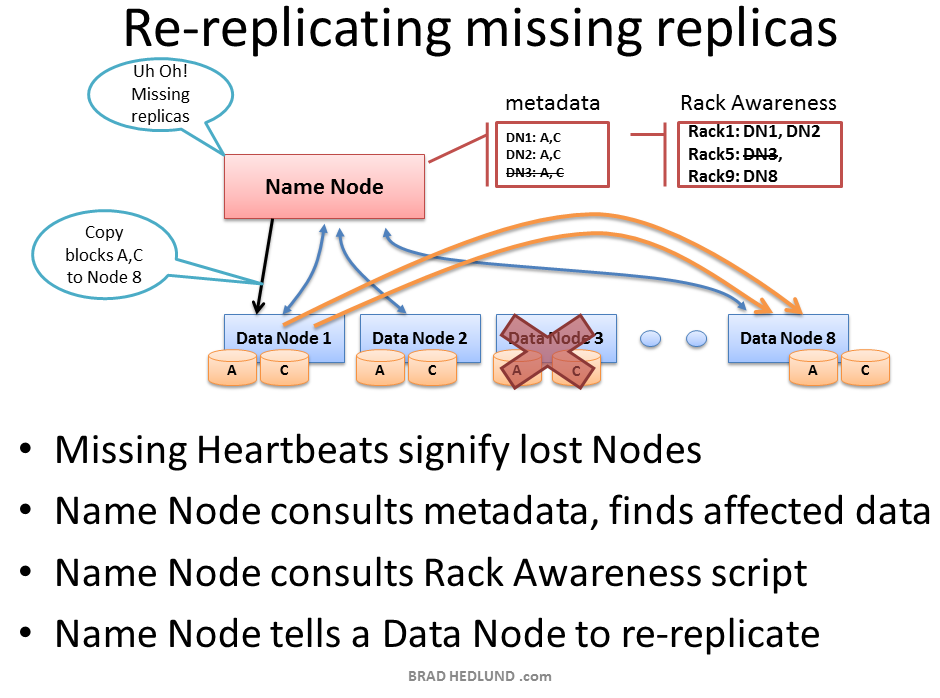
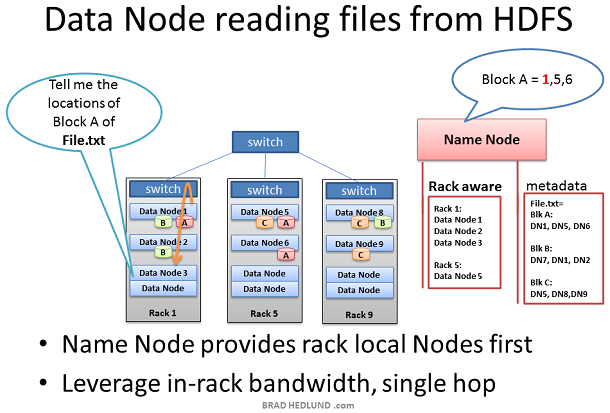
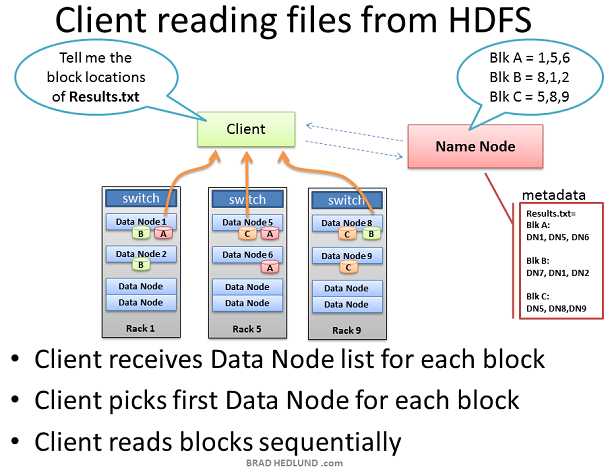


Map Reduce- Parallel processing of large data


§ Hive - Hadoop data
warehouse

§ Hbase - NoSQL key value pair database
· Written in: Java
· Main point: Billions of rows X millions of columns
· License: Apache
· Protocol: HTTP/REST (also Thrift)
· Modeled after Google's BigTable
· Uses Hadoop's HDFS as storage
· Map/reduce with Hadoop
· Query predicate push down via server side scan and get filters
· Optimizations for real time queries
· A high performance Thrift gateway
· HTTP supports XML, Protobuf, and binary
· Jruby-based (JIRB) shell
· Rolling restart for configuration changes and minor upgrades
· Random access performance is like MySQL
· A cluster consists of several different types of nodes
Best used: Hadoop is probably still the best way to run Map/Reduce jobs on huge datasets. Best if you use the Hadoop/HDFS stack already.
For example: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.

§ Mahout - Machine Learning
§ Pig - Scripting language
§ Hue - Graphical user interface
§ Whirr- libraries for running cloud services
§ Oozie - Workflow engine
§ Zookeeper - Workflow manager
§ Avro - Serialization
§ Flume - Streaming
§ Sqoop - RDBMS connectivity
§ Chukwa - Data Collection
No comments:
Post a Comment